


Expert Discusses Human-AI Cooperation at Whiting School Event
On October 23, 2025, the Whiting School of Engineering’s Department of Computer Science welcomed Aaron Roth, a renowned professor of computer and cognitive science from the University of Pennsylvania, to present his insights on human-AI collaboration. The talk, titled “Agreement and Alignment for Human-AI Collaboration,” explored findings from three significant papers, including “Tractable Agreement Protocols” and “Collaborative Prediction: Tractable Information Aggregation via Agreement.”
As artificial intelligence continues to permeate various sectors, researchers are increasingly focused on how these technologies can assist humans in making critical decisions. Roth illustrated this concept using the example of AI in medical diagnostics, where AI systems predict patient conditions based on historical data, such as previous diagnoses and symptoms. The AI’s predictions are then evaluated by medical professionals who can either concur or challenge these insights based on their clinical expertise.
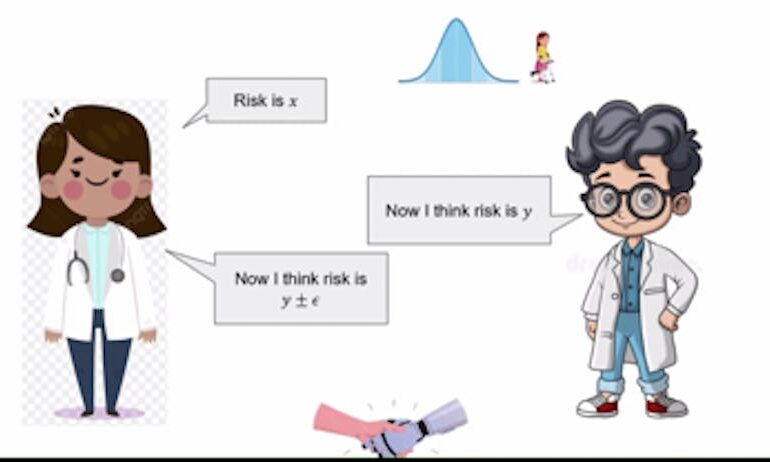
In situations of disagreement, Roth explained that both the AI model and the doctor have the opportunity to refine their opinions through a finite series of discussions. This iterative process allows them to integrate their distinct perspectives, ultimately leading to a consensus. This collaborative agreement hinges on a concept Roth refers to as a “common prior,” where both parties start with the same foundational assumptions about the world, despite having access to different pieces of evidence. He labels this dynamic as Perfect Bayesian Rationality, where each participant understands the general knowledge of the other while remaining unaware of specific details.
Despite its theoretical appeal, Roth acknowledged the challenges of establishing a common prior in practice. The complexities of the real world can hinder the achievement of complete agreement, particularly when addressing multifaceted issues such as hospital diagnostic codes. To navigate these challenges, Roth introduced the idea of calibration, which serves as a benchmark for evaluating claims made by both parties.
He provided an analogy involving weather forecasting to explain calibration. “You can sort of design tests such that they would pass those tests if they were forecasting true probabilities,” Roth stated. This concept extends to conversation calibration, a mechanism that allows the AI and doctor to base their claims on each other’s previous assertions. For example, if an AI estimates a 40% risk associated with a treatment while a doctor assesses it at 35%, the AI would adjust its subsequent risk assessment to a figure between these two values, gradually converging towards an agreement.
Roth emphasized that this discussion assumes both parties share the same end goal, but real-world scenarios may complicate this alignment. In cases where an AI model is developed by a pharmaceutical company, concerns may arise regarding potential biases in treatment recommendations. Roth advised that doctors should consult multiple AI models from different companies to mitigate these risks. By doing so, they can evaluate competing perspectives and select the best treatment options for their patients. This competitive landscape would incentivize LLM (large language model) providers to create more unbiased and aligned models.
Roth concluded his presentation by addressing the concept of real probabilities, which reflect the genuine dynamics of the world. While these probabilities offer the most accurate and unbiased representations, achieving such precision is often unnecessary. In many cases, it suffices to derive reliable estimates from data without delving into the complexities of perfect reasoning. Through effective collaboration, doctors and AI can work together to establish agreements on appropriate treatments, diagnoses, and more, enhancing patient care and decision-making processes.


